HTML meta 详解
时间:2017-08-17用于告知浏览器以何种版本来渲染页面。
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"/> //指定IE和Chrome使用最新版本渲染当前页面
name
name属性的定义是属于 document-level metadata,不能和以下属性同时设置: itemprop, http-equiv 或 charset。
该元数据名称与content属性包含的值相关联。 name属性的可能值为:
application-name
定义在网页中运行的应用程序的名称。
author
用于标注网页作者。
description
包括一个关于页面内容的缩略而精准的描述。一些浏览器,如Firefox和Opera,会使用这个当做网页书签的默认描述。
generator
用于标明网页是什么软件做的。
keywords
用于告诉搜索引擎,你网页的关键字
revisit-after
如果页面不是经常更新,为了减轻搜索引擎爬虫对服务器带来的压力,可以设置一个爬虫的重访时间。如果重访时间过短,爬虫将按它们定义的默认时间来访问。举例:
<meta name="revisit-after" content="7 days">
renderer
renderer是为双核浏览器准备的,用于指定双核浏览器默认以何种方式渲染页面。比如说360浏览器。举例:
<meta name="renderer" content="webkit"> //默认webkit内核 <meta name="renderer" content="ie-comp"> //默认IE兼容模式 <meta name="renderer" content="ie-stand"> //默认IE标准模式
referrer
referrer 控制document发起的Request请求中附加的Referer HTTP header(https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/Referer),相应的值在content中:
| content | 含义 |
|---|---|
| no-referrer | 不发送HTTP Referer头 |
| origin | 发送document的origin |
| no-referrer-when-downgrade | 将origin作为referer发送到和当前页面同等安全的URLs(https-> https),但不会将origin发送到不安全的URLS(https-> http)。这是默认行为。 |
| origin-when-crossorigin | same-origin的请求,发送的完整URL(剥离参数),但在其他情况下只发送origin |
| unsafe-URL | same-origin 或 cross-origin的请求,将发送完整的URL(剥离参数) |
robots
robots用来告诉爬虫哪些页面需要索引,哪些页面不需要索引。
| 值 | 描述 | Used By |
|---|---|---|
| index | 允许robot索引本页面(默认) | All |
| noindex | 不允许robot索引本页面 | All |
| follow | 允许搜索引擎继续通过此网页的链接索引搜索其它的网页(默认) | All |
| nofollow | 搜索引擎不继续通过此网页的链接索引搜索其它的网页 | All |
| none | 相当于noindex,nofollow | |
| noodp | 禁止使用Open Directory Project描述(如果有的话)作为搜索引擎结果中的页面描述。 | Google, Yahoo, Bing |
| noarchive | 要求搜索引擎不缓存页面内容 | Google, Yahoo, Bing |
| nosnippet | 禁止在搜索引擎结果中显示该页面的任何描述。 | Google, Bing |
| noimageindex | 要求此页面不作为引用页面的索引图像的显示。 | |
| nocache | 和noarchive同义 | Bing |
viewport
提供了关于viewport初始大小的大小的提示。仅供移动设备使用。
相关文章
 HTML页面跳转及参数传递问题这篇文章给大家详细介绍了HTML页面跳转及参数传递问题,需要的朋友参考下吧
HTML页面跳转及参数传递问题这篇文章给大家详细介绍了HTML页面跳转及参数传递问题,需要的朋友参考下吧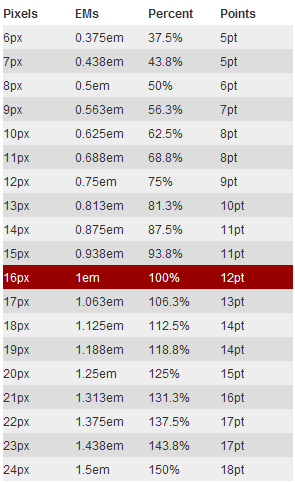 详解CSS3 rem(设置字体大小) 教程本篇文章主要介绍了详解CSS3 rem(设置字体大小) 教程,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起
详解CSS3 rem(设置字体大小) 教程本篇文章主要介绍了详解CSS3 rem(设置字体大小) 教程,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起 CSS: hover选择器的使用详解这篇文章主要介绍了CSS: hover选择器的使用详解,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随
CSS: hover选择器的使用详解这篇文章主要介绍了CSS: hover选择器的使用详解,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随 浅谈css3新单位vw、vh、vmin、vmax的使用详解这篇文章主要介绍了浅谈css3新单位vw、vh、vmin、vmax的使用详解的相关资料,小编觉得挺不错的,现在分享给大家,也
浅谈css3新单位vw、vh、vmin、vmax的使用详解这篇文章主要介绍了浅谈css3新单位vw、vh、vmin、vmax的使用详解的相关资料,小编觉得挺不错的,现在分享给大家,也 详解Sticky Footer 绝对底部的两种套路这篇文章主要介绍了详解Sticky Footer 绝对底部的两种套路,小编觉得挺不错的,现在分享给大家,也给大家做个参考。
详解Sticky Footer 绝对底部的两种套路这篇文章主要介绍了详解Sticky Footer 绝对底部的两种套路,小编觉得挺不错的,现在分享给大家,也给大家做个参考。 详解如何编写高效的 CSS 选择符本篇文章主要介绍了详解如何编写高效的 CSS 选择符,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起
详解如何编写高效的 CSS 选择符本篇文章主要介绍了详解如何编写高效的 CSS 选择符,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起
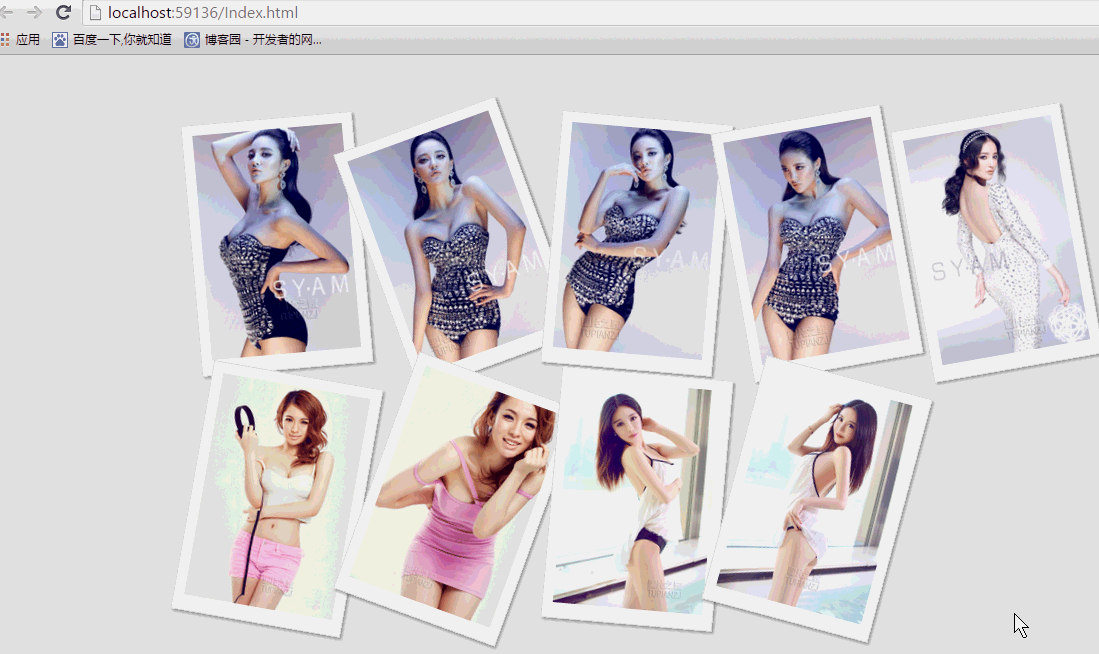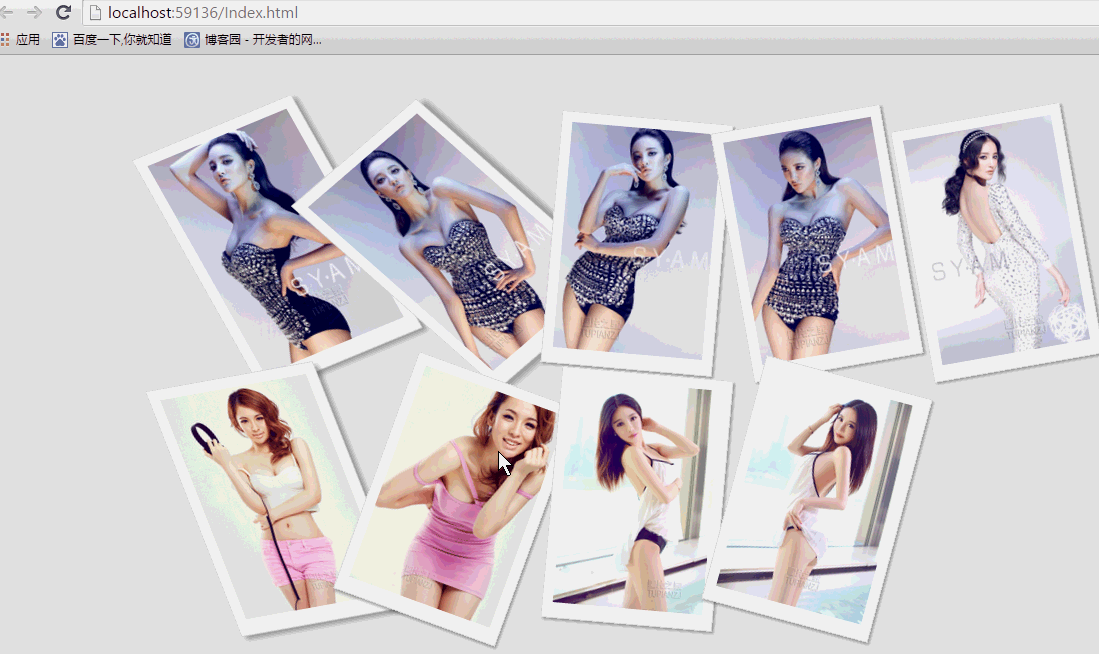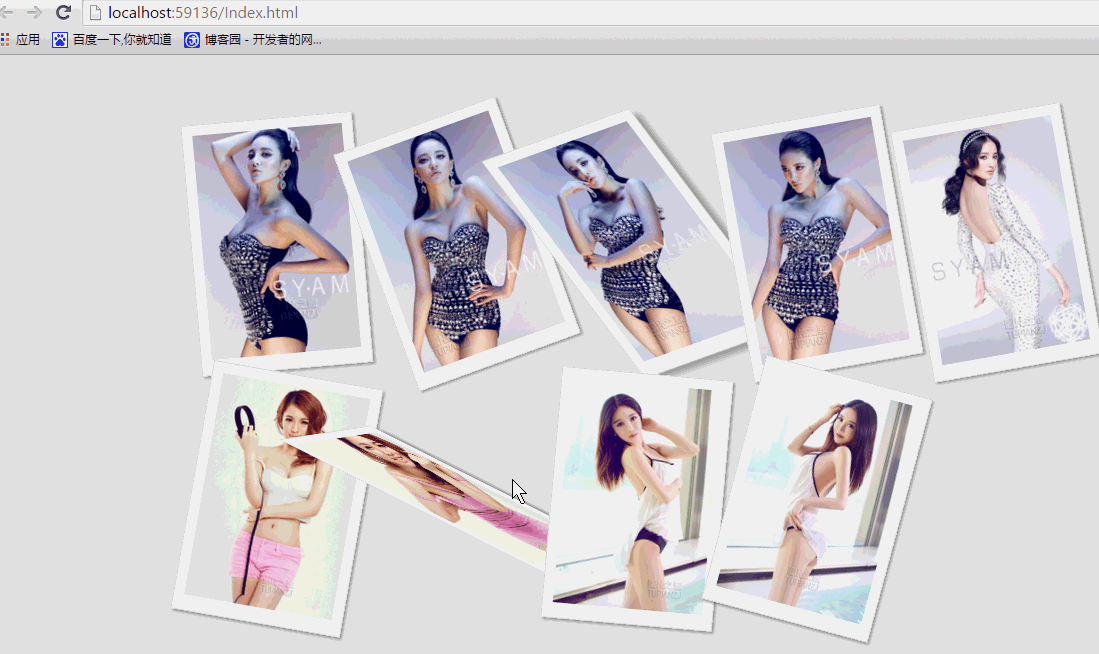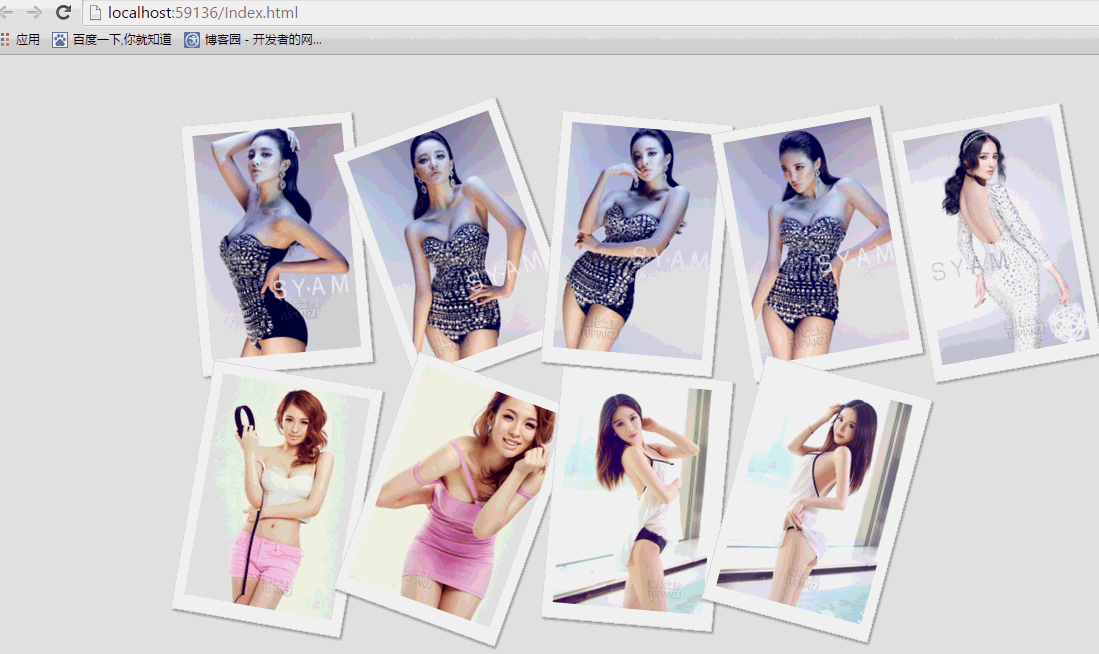 纯css实现照片墙3D效果的示例代码这篇文章主要介绍了纯css实现照片墙3D效果的示例代码,可以实现鼠标经过图片实现改变,具有一定的参考价值,感兴趣的小
纯css实现照片墙3D效果的示例代码这篇文章主要介绍了纯css实现照片墙3D效果的示例代码,可以实现鼠标经过图片实现改变,具有一定的参考价值,感兴趣的小 纯 Css 绘制扇形的方法示例本篇文章主要介绍了纯 Css 绘制扇形的方法示例,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过
纯 Css 绘制扇形的方法示例本篇文章主要介绍了纯 Css 绘制扇形的方法示例,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过