Java中synchronized 的4个优化技巧
时间:2022-12-10前言
synchronized 在 JDK 1.5 时性能是比较低的,然而在后续的版本中经过各种优化迭代,它的性能也得到了前所未有的提升,上一篇文章我们谈到了锁膨胀对 synchronized 性能的提升,然而它也只是“众多” synchronized 性能优化方案中的一种,那么我们本文就来盘点一下 synchronized 的核心优化方案。
synchronized 核心优化方案主要包含以下 4 个:
- 锁膨胀
- 锁消除
- 锁粗化
- 自适应自旋锁
1.锁膨胀
我们先来回顾一下锁膨胀对 synchronized 性能的影响,所谓的锁膨胀是指 synchronized 从无锁升级到偏向锁,再到轻量级锁,最后到重量级锁的过程,它叫做锁膨胀也叫做锁升级。
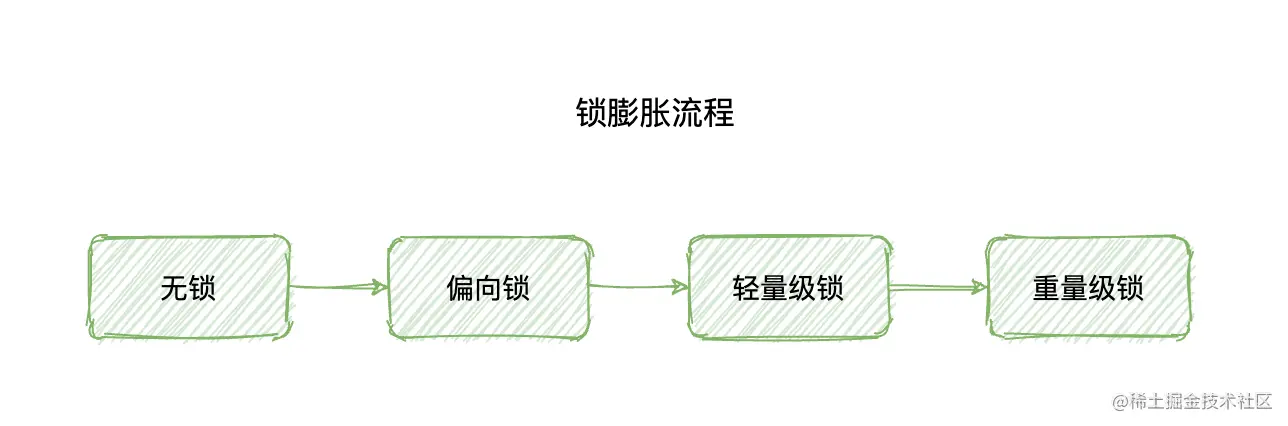
JDK 1.6 之前,synchronized 是重量级锁,也就是说 synchronized 在释放和获取锁时都会从用户态转换成内核态,而转换的效率是比较低的。但有了锁膨胀机制之后,synchronized 的状态就多了无锁、偏向锁以及轻量级锁了,这时候在进行并发操作时,大部分的场景都不需要用户态到内核态的转换了,这样就大幅的提升了 synchronized 的性能。
PS:至于为什么不需要用户态到内核态的转换?请移步到锁膨胀的那篇文章:《Java中的synchronized 优化方法之锁膨胀机制》。
2.锁消除
很多人都了解 synchronized 中锁膨胀的机制,但对接下来的 3 项优化却知之甚少,这样会在面试中错失良机,那么我们本文就把这 3 项优化单独拎出来讲一下吧。
锁消除指的是在某些情况下,JVM 虚拟机如果检测不到某段代码被共享和竞争的可能性,就会将这段代码所属的同步锁消除掉,从而到底提高程序性能的目的。
锁消除的依据是逃逸分析的数据支持,如 StringBuffer 的 append() 方法,或 Vector 的 add() 方法,在很多情况下是可以进行锁消除的,
比如以下这段代码:
public String method() {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 10; i++) {
sb.append("i:" + i);
}
return sb.toString();
}以上代码经过编译之后的字节码如下:
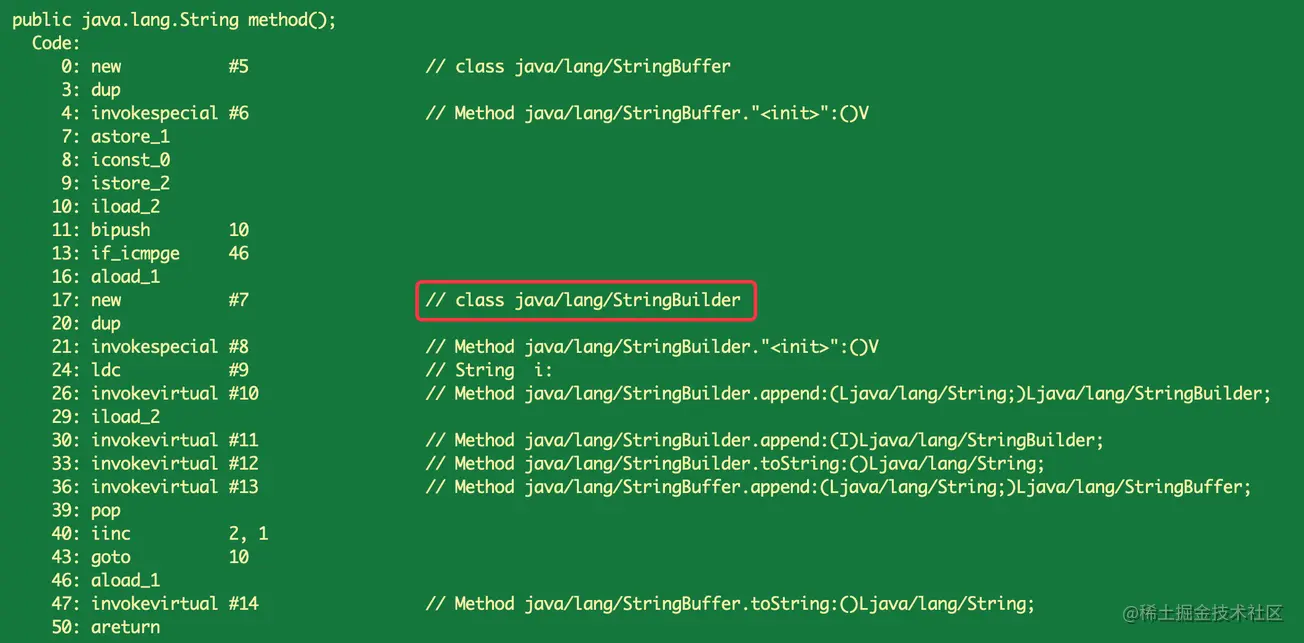
从上述结果可以看出,之前我们写的线程安全的加锁的 StringBuffer 对象,在生成字节码之后就被替换成了不加锁不安全的 StringBuilder 对象了,原因是 StringBuffer 的变量属于一个局部变量,并且不会从该方法中逃逸出去,所以此时我们就可以使用锁消除(不加锁)来加速程序的运行。
3.锁粗化
锁粗化是指,将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁。
我只听说锁“细化”可以提高程序的执行效率,也就是将锁的范围尽可能缩小,这样在锁竞争时,等待获取锁的线程才能更早的获取锁,从而提高程序的运行效率,但锁粗化是如何提高性能的呢?
没错,锁细化的观点在大多数情况下都是成立了,但是一系列连续加锁和解锁的操作,也会导致不必要的性能开销,从而影响程序的执行效率,比如这段代码:
public String method() {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 10; i++) {
// 伪代码:加锁操作
sb.append("i:" + i);
// 伪代码:解锁操作
}
return sb.toString();
}这里我们不考虑编译器优化的情况,如果在 for 循环中定义锁,那么锁的范围很小,但每次 for 循环都需要进行加锁和释放锁的操作,性能是很低的;但如果我们直接在 for 循环的外层加一把锁,那么对于同一个对象操作这段代码的性能就会提高很多,
如下伪代码所示:
public String method() {
StringBuilder sb = new StringBuilder();
// 伪代码:加锁操作
for (int i = 0; i < 10; i++) {
sb.append("i:" + i);
}
// 伪代码:解锁操作
return sb.toString();
}锁粗化的作用:如果检测到同一个对象执行了连续的加锁和解锁的操作,则会将这一系列操作合并成一个更大的锁,从而提升程序的执行效率。
4.自适应自旋锁
自旋锁是指通过自身循环,尝试获取锁的一种方式,伪代码实现如下:
// 尝试获取锁
while(!isLock()){
}自旋锁优点在于它避免一些线程的挂起和恢复操作,因为挂起线程和恢复线程都需要从用户态转入内核态,这个过程是比较慢的,所以通过自旋的方式可以一定程度上避免线程挂起和恢复所造成的性能开销。
但是,如果长时间自旋还获取不到锁,那么也会造成一定的资源浪费,所以我们通常会给自旋设置一个固定的值来避免一直自旋的性能开销。然而对于 synchronized 关键字来说,它的自旋锁更加的“智能”,synchronized 中的自旋锁是自适应自旋锁,这就好比之前一直开的手动挡的三轮车,而经过了 JDK 1.6 的优化之后,我们的这部“车”,一下子变成自动挡的兰博基尼了。

自适应自旋锁是指,线程自旋的次数不再是固定的值,而是一个动态改变的值,这个值会根据前一次自旋获取锁的状态来决定此次自旋的次数。比如上一次通过自旋成功获取到了锁,那么这次通过自旋也有可能会获取到锁,所以这次自旋的次数就会增多一些,而如果上一次通过自旋没有成功获取到锁,那么这次自旋可能也获取不到锁,所以为了避免资源的浪费,就会少循环或者不循环,以提高程序的执行效率。简单来说,如果线程自旋成功了,则下次自旋的次数会增多,如果失败,下次自旋的次数会减少。
总结
本文我们介绍了 4 种优化 synchronized 的方案,其中锁膨胀和自适应自旋锁是 synchronized 关键字自身的优化实现,而锁消除和锁粗化是 JVM 虚拟机对 synchronized 提供的优化方案,这些优化方案最终使得 synchronized 的性能得到了大幅的提升,也让它在并发编程中占据了一席之地。
到此这篇关于Java中synchronized 的4个优化技巧的文章就介绍到这了,更多相关synchronized 优化内容请搜索html5模板网以前的文章希望大家以后多多支持html5模板网!
 Java中HashMap 中的一个坑这篇文章主要介绍了Java中HashMap中的一个坑,文章围绕主题展开详细的内容介绍,具有一定的参考价价值,需要的小伙伴可以
Java中HashMap 中的一个坑这篇文章主要介绍了Java中HashMap中的一个坑,文章围绕主题展开详细的内容介绍,具有一定的参考价价值,需要的小伙伴可以