织梦cms如何防采集
时间:2014-08-26织梦cms防采集妙招可用以下几点:
1、调整模板数据调用规则与新内容块布置
新内容块产生将页面主题关键词更分散一些,同时调整数据调用规则,让仿制站点的数据与自身页面数据产生差异性,降低复制网站SEO问题的负面影响。
2、找到防止内容采集的办法
DeDeCMS自身有防采集混淆字符串的功能,但这种防采集的办法对SEO很不利,你总不想让搜索蜘蛛看到网页中有不少隐藏文本吧,而且这些文本会影响蜘蛛对信息块主题的判断,影响关键词排名,其实,DeDeCMS没有根本性的防采集的方法,道高一尺魔高一丈啊,只要你的信息通过页面的方式发布出来,总能找到采集的方法;综合网上收集的信息,我采纳了两种办法,只能放置最初级的采集:
(1)办法一:复制网页正文内容时自动添加版权信息
JavaScript代码
<script language="javascript" type="text/javascript">
<!--
document.body.oncopy = function () {
setTimeout( function () {
var text = clipboardData.getData("text");
if (text) {
texttext = text + "\r\n(这里是你的文章版权信息,去掉括号):"+location.href;
clipboardData.setData("text", text);
}
}, 100 )
}
-->
</script>
将以上代码放置在文章页模板中正文结束后面即可。我测试了下该方法,只针对IE浏览器有效,而Firefox、遨游、Google Chrome均无效。
(2)办法二:使页面代码具有唯一性
一般别人采集的时候都是要获取内容开始的代码和结束的代码,而且要唯一性的,所以填的开始代码大多是:<divclass="title">。这样,我们在这个class后面加上文章的ID值,改成这样<div class="title"id="{dede:field.id/}">,这里{dede:field.id/}在dedecms中是获取当前文章的ID值,那么生成的每一篇文章的ID值都不一样,这里的开始代码也就都不一样了,这样别人就采集不到了,采一次只能采一篇。
我们制作模板的时候在在body标记附近的<div class="abc">修改成<divclass="{dede:field.id/}abc">,注意是空格+{dede:field.id/},这样div的class还是没有变,但产生了<div class="abc文档ID">,这段代码在每篇文章的内文页均是唯一性的,或者在html标记里插入id={dede:field.id/},比如:<divid={dede:field.id/}>与<bodyid={dede:field.id/}>,这里{dede:field.id/}在dedecms中是获取当前文章的ID值,这样别人就采集不到了,采一次只能采一篇。当然,别人可以使用过滤规则来去掉,但是假如我在所有的class里插入文档ID,或者插入id=文档ID这样的。那他就只能采集整个页面,然后再过滤,使采集变得更加复杂。
缺点:如果插入{dede:field.id/}不够多的话别人可以用过滤规则过滤掉。但是对于一些站群采集软件来说,这一招足以防止他们采集了!
相关文章
 织梦cms实现带缩略图文章,标题里显示一个‘图dedecms 让带有图片的文章,标题后面加一个图字,没有图片则不加 在arclist 标签下循环出的对应位置中加入 [field:lit
织梦cms实现带缩略图文章,标题里显示一个‘图dedecms 让带有图片的文章,标题后面加一个图字,没有图片则不加 在arclist 标签下循环出的对应位置中加入 [field:lit- 织梦cms如何每分钟审核一篇文章并且生成首页dede 每分钟审核一篇文章并且生成首页: 直接进入正题: plus下新建文件 makeid.php 内容如下: ?php$lasttime=filemtime($_SERV
- 织梦cms如何调用栏目页及单独内容页很多站长在套DEDE站的时候,可能一直被一个问题困惑,就是,如何将已经做成单页的栏目内容调用到首页来。 常用的
- 织梦cms出现DedeTag Engine Create File False的解决在使用 dede cms 5.7sp1的时候出现了DedeTag Engine Create File False的状况,当然也不只是现在才碰到的,以前也碰到过 下面包
 织梦cms seo优化技巧1,将当前位置的“主页”字样,改为“你自己的网站名称”。这虽然是很小的事情,但首先它增强了网站的内链接,
织梦cms seo优化技巧1,将当前位置的“主页”字样,改为“你自己的网站名称”。这虽然是很小的事情,但首先它增强了网站的内链接,- 织梦cms增加php函数功能及在列表页获取当前栏目打开include/common.func.php,在其中任一行(?与?的中间任一行)中加上如下函数. function dynamic_num($current_id){global $dsql;$t_num =
 织梦dedecms后台增加logo上传功能用过dedecms的朋友都知道,织梦cms后台系统基本参数里是无法直接上传图片的,我们更换logo图只能到ftp里替换,非常的不方便
织梦dedecms后台增加logo上传功能用过dedecms的朋友都知道,织梦cms后台系统基本参数里是无法直接上传图片的,我们更换logo图只能到ftp里替换,非常的不方便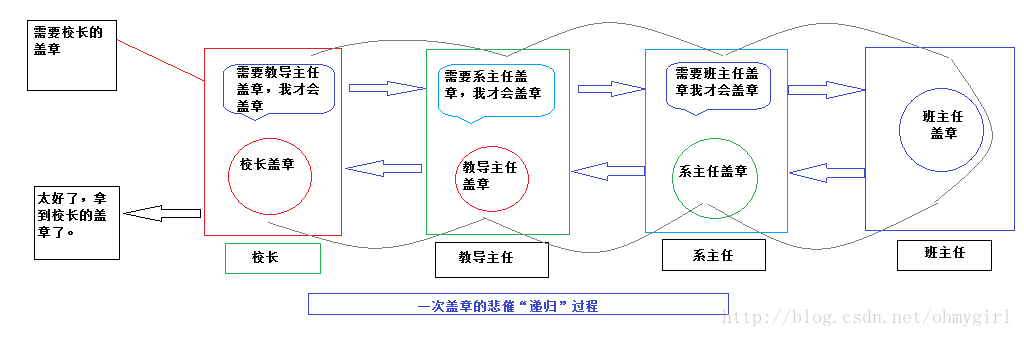 PHP中递归的实现实例详解递归(http:/en.wikipedia.org/wiki/Recursive)是一种函数调用自身(直接或间接)的一种机制,这种强大的思想可以把某些复杂的概
PHP中递归的实现实例详解递归(http:/en.wikipedia.org/wiki/Recursive)是一种函数调用自身(直接或间接)的一种机制,这种强大的思想可以把某些复杂的概